Rl Web Security
Date:
Since my partner is a web security expert, I often end up having long discussions about internet security, even though my personal knowledge and research is in a very different area.
That has recently gotten us to thinking about the intersection of reinforcement learning and web security. Though at first these may seem like two disparate areas, as anyone who has had experience talking at length with another person about their specific research area will know, eventually there are many commonalities that can be found between the two.
These connections were relatively easy to make since my own personal experience in reinforcement learning research is in the area of human-inspired RL. To the best of my understanding, web security revolves around the ways that humans and automated systems interact with web based services. Because of this, RL agents designed with a human-centric approach seem relatively well suited for interacting with these systems.
The first use case for such RL systems that immediately jumps to mind is in performing some type of testing for existing web services or ones in development. I do have some minor experience in web application software testing, though it was in performance specifically and centered moreso around timing and user satisfaction rather than data security.
As with all potential use-cases of RL it is a fun mental exercise to break down the state, environments, actions, and rewards to see if we can immediately make sense of what the system would look like and how it would perform its task. Additionally this is useful in determining if existing solutions are sufficient or better suited to the tasks that are in question. We can use the classic diagram from Sutton and Barto as a reference for the interaction between these parts.
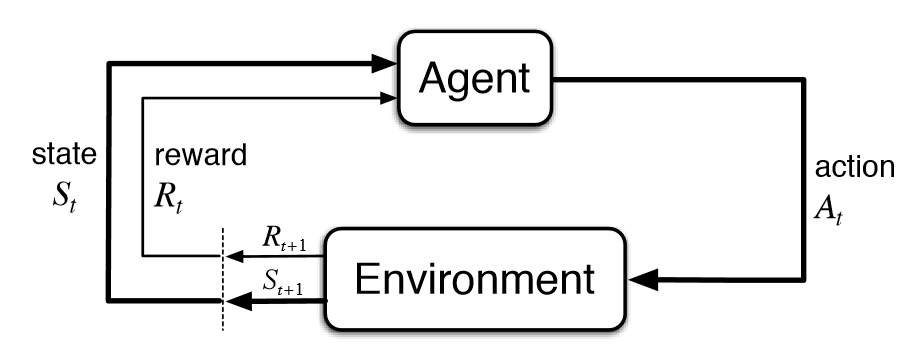
For the environment, we would likely want to limit our area of investigation to a particular website or web based application/system to limit the space we are interested in. However, there are many possible structures for how information is represented on the web, and we should additionally limit, at least for our brief discussion, how this information is represented. One particularly useful manner is provided by the REST API or Representational State Transfer Application Programing Interface. Even without knowing much about it, this seems like a great way to structure our RL system, State (the focus of all RL systems) is right in the name!
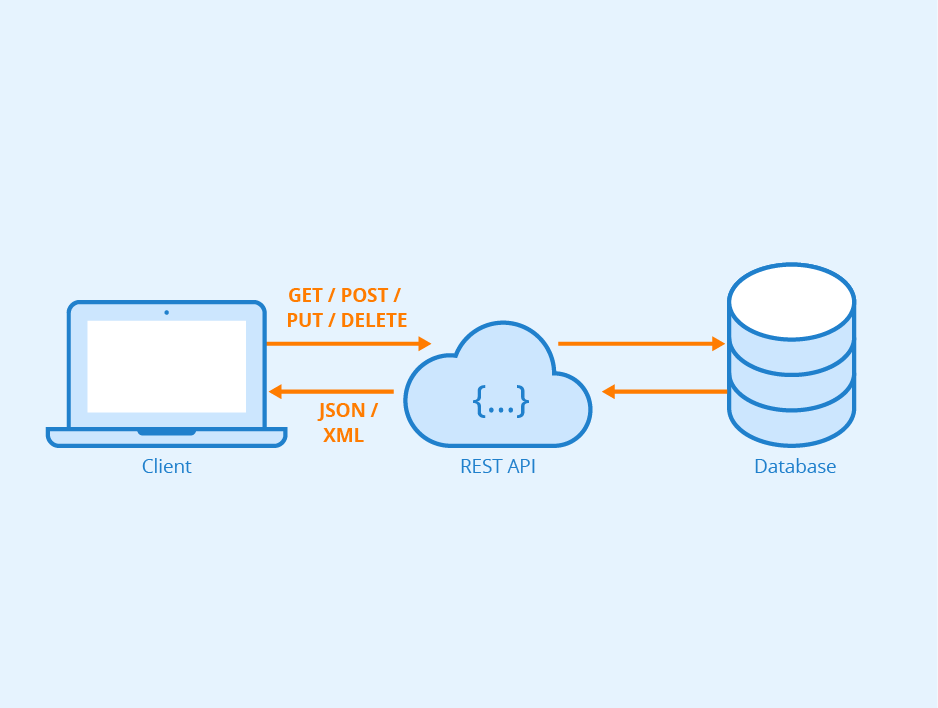
Not only does the REST API provide a manner for representing data, more importantly it describes how the user, in this case our RL algorithm, interacts with a web based system. Just looking at the two diagrams shown previously we can easily draw direct connections between their functionalities.
Generally the information contained in a REST API based response from a web server is contained in a specific format such as HTML, XML, or JSON depending on the application. If we were to build a real RL system we would likely again want to narrow down (you are likely starting to see a trend) the scope by selecting one of these formats. Alternatively we could try training a more general RL system with either a logic based preprocessing step unique to each of the representation methods, or some other information structuring approach.
Although it may seem like an implementation level or ML engineering based question of how exactly this information is processed prior to being inputted into the RL system, much of the current research around logical based AI, neuro-symbolic AI, fuzzy logic, logic nets and so on seems highly relevant in the case of the environment we are interested in. All of those domains would probably have a useful insight into how the information should be structured and manipulated to best replicate something like general human behavior when interacting with a web based system. However, which and how those domains impact our RL system would depend on what exactly the goals are, and while it is interesting I should limit the scope (pun intended) of this blog post and move onto the reward function.
Now that we have a rough sketch for our environment, actions, and how both of those are going to be represented, we can begin looking at the reward and how we would train such a system. As I mentioned at the beginning, I am most experienced in building RL systems that in some way replicate how a human might interact with a similar system, given their limited attention and cognitive resources. With our current example, this might seem like a good application in inverse reinforcement learning, using human or expert behavior as a basis for training our RL algorithm. That might be a good approach if we are interested in creating the same effect as ‘smart scripts’ that could be used to stress test a system in a similar manner to real human users.
Another approach that is very different is more in the domain of what initially motivated this blog post, in the area of web security. Here we have a similar environment and action space, but the goal is very different. Instead of just replicating general human interaction with a web system, we want to answer the question of how secure our system is. As before one idea immediately jumps to mind, provided by the structure of web-based CTF (capture the flag) challenges which consist of a human interacting with some web system with the goal of collecting some hidden information (the flag).
This type of expert level behavior may require far too much generalization to be trainable from human experience, even with all of the advances of language models and other approaches that leverage massive datasets related to a specific task. Though it does seem like the type of thing we could expect web security researchers and experts to be using as a tool in the not too distant future. Since my own experience is less on the side of web security I won’t get too much into the details for fear of getting something wrong, though I likely have made some mistakes already. But nonetheless this does seem like an interesting application to me that I’ll continue to think about as my research continues.